健康160的kubernetes日志采集落地的坎坷之路
引言
老东家的大佬基础架构方面做得比较好,日志打印都比较规范,还封装了日志组件,打印的日志不落盘,直接往 Kafka 送。
这样日志收集就省了很多事情了,性能还好。
健康160就没这么好条件了,因为项目庞大,建设时间跨度很长,技术架构迭代过几次,导致有很多不同语言,不同框架的服务。日志打印也是五花八门。
在开始推进Kubernetes容器化的时候,无可避免地要涉及日志的收集,真正收集的时候,才感觉这五花八门的日志采集起来,有点难受。
我们虚拟机方案是每个服务都配置一下 Logstash 来采集和过滤消息,然后推送到 Kafka 消费。
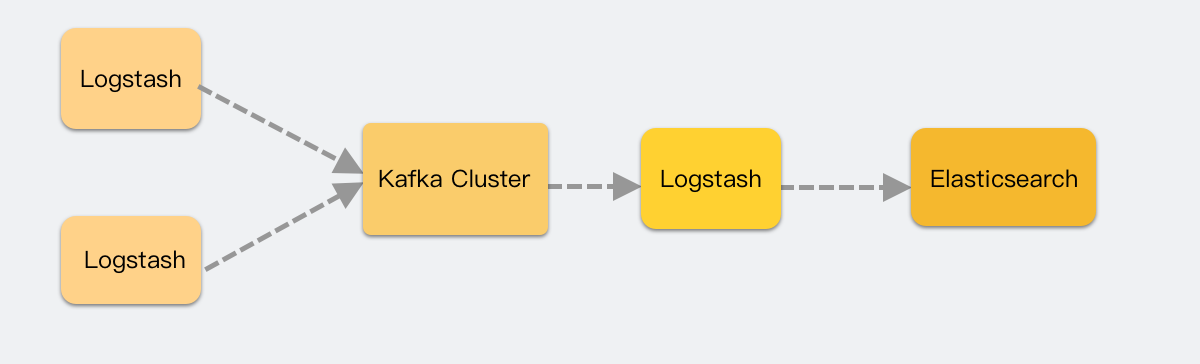
每个服务都要修改一下,来适配这个服务,这种刀耕火种的方式,感觉已经和时代脱轨了。我所期待的,是服务发到 k8s 后,就自动完成了日志的采集,不用配置 Logstash 了。加上 Logstash 是 Java 服务,资源占用不小,所以就把眼光瞄向基于 Fluent Bit的 日志Operator。
初探基于 FluentBit 的日志采集Operator
容器化的服务,我们会把日志输出到 stdout,而这些日志,会被容器收集起来放在/var/log/containers/*.log,所以我们只需要收集容器目录的日志就好。
基于 Fluent Bit 来做的 Kubernetes 日志采集的方案中,以 Fluent Operator 和 Logging Operator 最好。
它们默认都是用 Fluentbit 以 Deamonset形式部署,每个容器运行起来后,把宿主机的 /var/log/containers/ 目录挂进来,用 File Input 插件对该目录下的文件进行采集。
当时两个都支持 Fluent Bit 和 fluentd,都差不多。反而 Fluent Operator 的开箱即用做得更好些,基本 helm 简单配置下 values,安装就能用,Logging Operator 还需要一些额外的资源定义的配置才行。
于是就有了这篇文章:K8S日志收集 Fluent Operator 动态索引名的实现 当时还提了两个 PR 来支持这个改动 #1119 #1121
这时候采集大概是这样的,没有中间商赚差价。
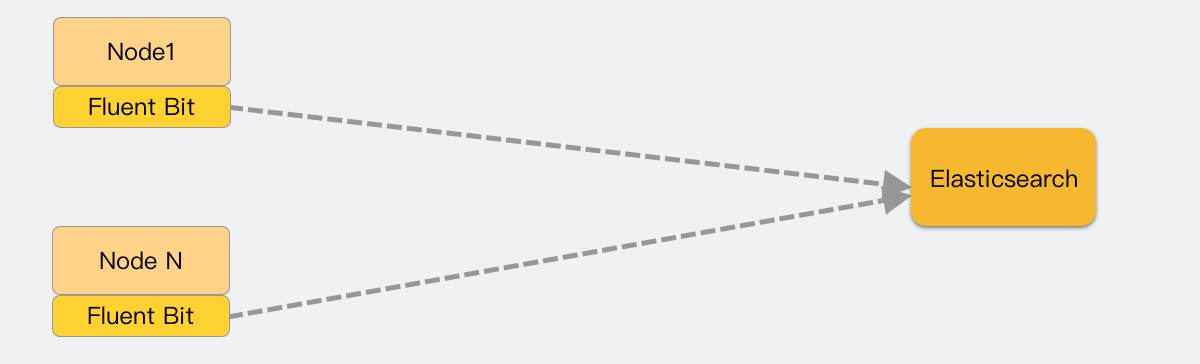
一开始,小日子看起来还是可以的,fluentbit 负载并不高,常年内存使用在 50mb 左右。
初遇挑战
异常堆栈多行文本合并问题
直到开发反馈说多行堆栈的内容没有合并到同个日志开始,幸福的日子就开始告一段落了。
于是开始动手,增加了Java MultilineParser 来匹配日志 见这个 PR #1138 ,并顺手修复了没有用匿名结构体,导致生成的资源配置和 CRD 定义的资源不一致的bug MultilineParser achieve an effect similar to embedding by using anonymous structs #1133
经过折腾,发现能采集日志,而且多行采集也没问题,就应用了这个改动。

日志采集暂停问题
没过几天,发现有些节点的日志采集停了,服务没日志了。再看该节点上的 Fluent Bit,相关节点内存占用都比较高,都到了分配的内存最高位。
看 Fluent Bit 的日志,发现
1 | [ warn] [input] emitter.59 paused (mem buf overlimit) |
当时 buffer 我用的是 memory,而不是 file,其实生产应该用 file 更好,可以分配更大的 buffer,而不用占用昂贵的内存。
想着内存不够,那就加多点,毕竟有时候输入过快,输出速度跟不上是很正常的,先提高内存来解燃眉之急。
回过头来,梳理了下,Fluent Bit buffer 消耗过多,猜测可能会以下几种情况:
- 高峰期消息生产实在太快,需要缓存来削峰,停过这段时间即可。
- multiline 匹配行还没遇到结束的 flag 的时候,要内存来保存,而大量的多行导致内存占用升高。
- 输出到 Elasticsearch 的速度过慢,无法及时消耗 input 的内容,导致内存堆高。
通过iotop -Po 只看进程,并且有 io 的进程,然后箭头左右控制,切换到 DISK WRITE 列 来观察,锁定一些输出高的进程。类似下面这样。
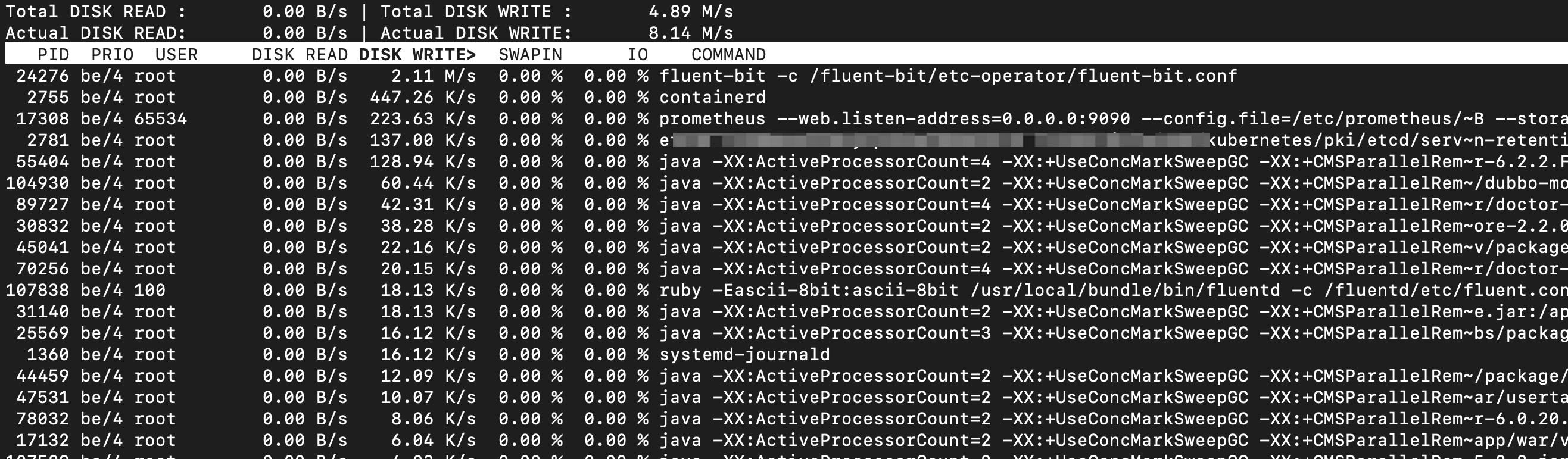
发现在出问题的几台机器,有新容器化项目在运行,输出的日志量是比较多,明显大于其它的机器。
而 multiline 插件的memory buffer 确实会导致内存升高。而且我们多语言环境,有些语言框架输出的多行文本和别人的不太一样,很难有一套正则能涵盖所有语言的多行的起始匹配,可能会导致超长 multiline 的产生。
当时用的 fluent-bit 2.2.2版本,不会因为 buffer 满,而限流输入端,可能还导致日志丢失。见 Issue https://github.com/fluent/fluent-bit/issues/8198 , 3.0.2之后是会限流输入端的。
再看 Fluent Bit 的日志,会发现一些推送到 Elasticsearch 429 状态的日志,基本就是 Elasticsearch 太过于繁忙,日志推送被 reject了,需要重试。
调整方案
至此,问题四面八方都有,四面楚歌,痛定思痛,唯有重新梳理流程,调整日志采集的架构的路子可以走了。
需求整理
整理了下需求如下:
- 能监控采集的服务,及时发现采集端的问题。
- 能图表化看到采集组件的各项指标,好确定调整是否有效果。
- 比较方便地分类服务,按类别应用不同的语言的采集规则。
- 提升推送吞吐量,避免日志积压在推送端。
采集流程调整
参考之前虚拟机的方案,调整后的架构如下:
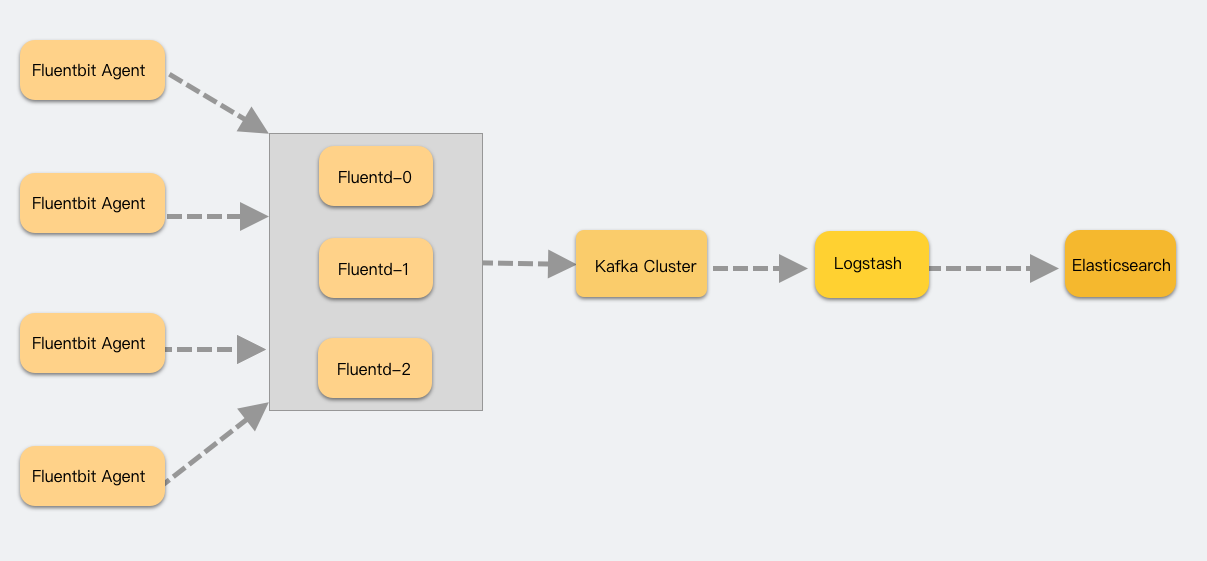
为什么搞了一个 fluentd 组出来?
主要是想减轻 FluentBit agent 的负载,FluentBit将其作为一个 demonset 的类型服务,一个节点有一个,如果它承担 Input 之外,还承担Filter 和 Output 的职责,很容易出现性能问题。而这个时候不好横向扩张来解决。
虽然可以做到为每个不同服务分组都建立一个 daemonset 的 FluentBit agent,来实现每台机有多个 agent 来处理,但是在现阶段下,一个节点一个 agent 来处理所有的日志 Input是没问题的。
Fluentbit 采集的日志,简单的 Parser 处理后,就直接 Forward 给 Fluentd 的service。fluentd 在这里用的是 StatefulSet类型,因为 buffer,cache之类的持久化存储,为了性能,使用的是 hostPath。
在 filter 和 output 遇到瓶颈的时候,是可以比较容易扩容来实现更高的数据处理的能力的。
日志采集Operator再选型
有了大致的方案和需求,就重新对社区的相关日志方案选型
| 能力 | Fluent Operator | Logging Operator |
|---|---|---|
| 支持 fluent+fluentd方案 | ✔ | ✔ |
| 有开箱即用的 grafana 面板 | ✖ | ✔ |
| 比较方便地分类服务,使用不同的采集规则 | ✖ | ✔ |
两个其实差别不大,但是在我额外关注的点上,Logging Operator 要做得更好点。有 CNCF 的孵化,还是有后劲更足些。
Logging Operator有个抽象得不错的资源叫 Flow,可以比较轻松来根据 label 匹配不同的 pod 的日志进行采集。这在后续我区分不同的服务来用不同的规则的时候,起到很大的便利。
举个例子,我要匹配出label language=python 的服务进行使用detectExceptions 插件、record_transformer插件、record_modify 插件处理后,output 到 kafka 的相关 output 的时候,大概如下:
1 | apiVersion: logging.banzaicloud.io/v1beta1 |
有了 match,就可以针对不同的服务,使用不同的规则来精准匹配日志。
这里值得提醒的是,Fluentd的 filter 使用的插件越多,处理速度就越慢。比如上面的 detectExceptions 服务就迫使 Fluentd 只能工作在单 worker 模式下,性能大打折扣。
改动小结
让我们再总结一下。
之前的方案,所有的日志都用同一套采集规则,不够灵活。经过整改后我按照语言的维度来划分不同的 Flow,来应用不同的采集规则。
Buffer 和 Cache 从 Memory 改为 File,使用 hostPath 挂载的本地盘,保障写入的性能。
另外 Fluentbit 只承担 Input 和简单的 Parser任务,复杂和性能损耗比较大的 Filter 和耗时的推送交给 可以横向扩容的Fluentd。
Output 原先是直接推送到 ES集群,现在改为推送到 Kafka 集群,我对 Kafka 集群进行了基准测试,写入能力大概在 200mb/s 这个大大超出了我们的output 的流量,哪怕是高峰时期。
另外我们对 Fluentbit 和 Fluentd 的指标进行采集,并通过 Grafana 展示,容易一目了然观测过去和当下的日志采集情况。
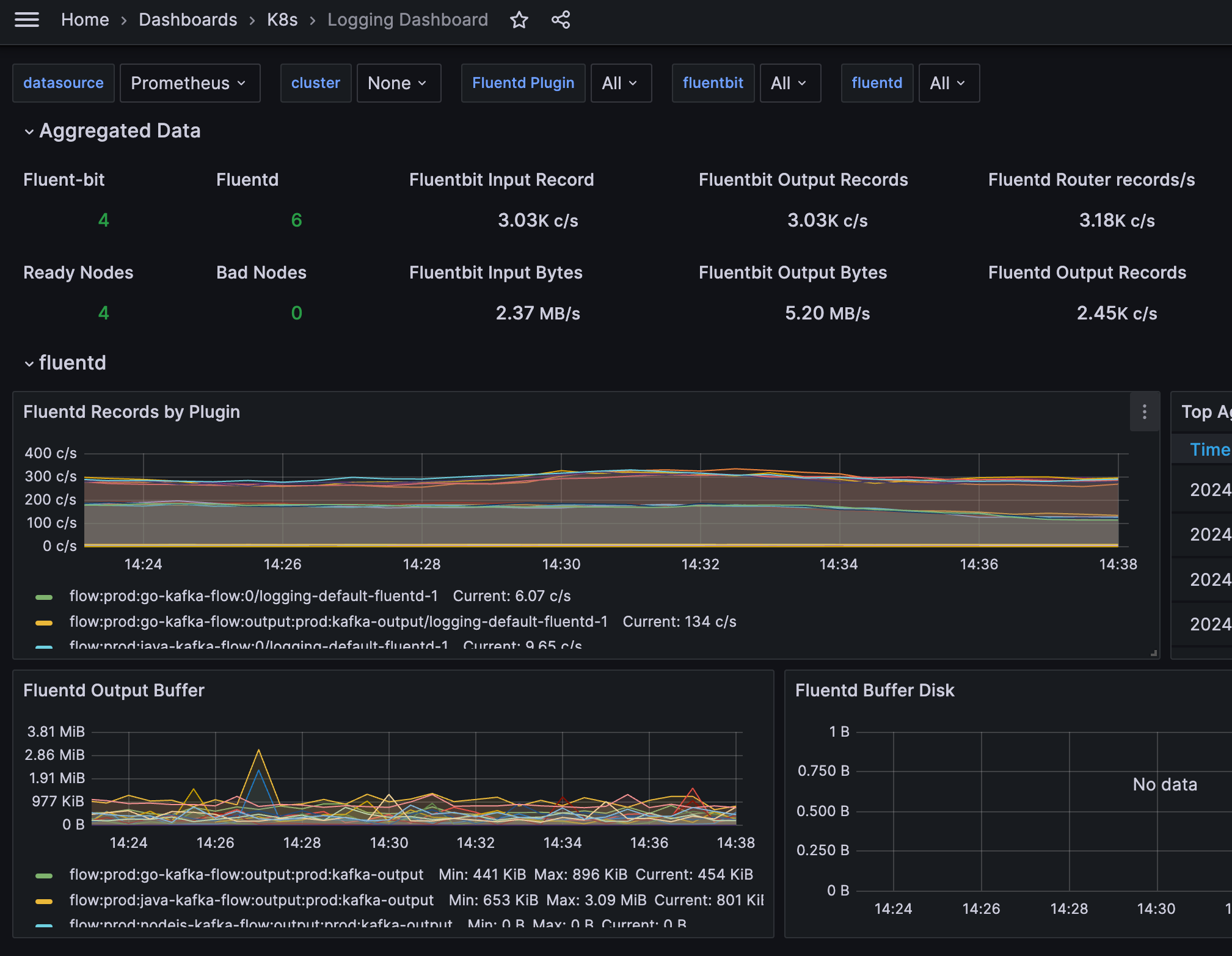
这样一来,职责清晰,也有较大的弹性来应对未来的流量暴涨。
掐指一算,妥妥的,然而…
新的挑战
Output Buffer 存满
然而在我认为最不可能发生问题的环节,偏偏发生了。Output 到 Kafka 的吞吐量,居然还不如之前的 Elasticsearch!
Output Buffer 很快就又堆满了。
经过排查,发现是 Logging Operator Fluentd内置的 Kafka 插件,默认用的是 ruby-kafka,性能非常差。可以改为用 rdkafka,这个是 c 语言实现的插件,性能比 ruby-Kafka 好很多。
我用的 Logging Operator 当前最新版本是 4.8.0,其用的 fluend:v1.16-4.8-full 镜像没有打包 rdkafka,另外 Logging Operator 并不支持 rdkafka 客户端的相关配置。
问题解决
知道了问题,就好解决了,我从新打包了一个镜像,把 rdkafka 打包进去,并修改了下 Logging Operator Kafka output支持该插件配置,并兼容之前的配置。
相关改动,我也提交到了社区,并被采纳了,不出意外的话,在 4.9.0 版本就可以体验。
具体 PR 见fluentd-images#/142 、logging-operator#1780
启用rdkafka client也非常简单,在原来的Kafka output 配置上增加 use_rdkafka: true 如
1 | apiVersion: logging.banzaicloud.io/v1beta1 |
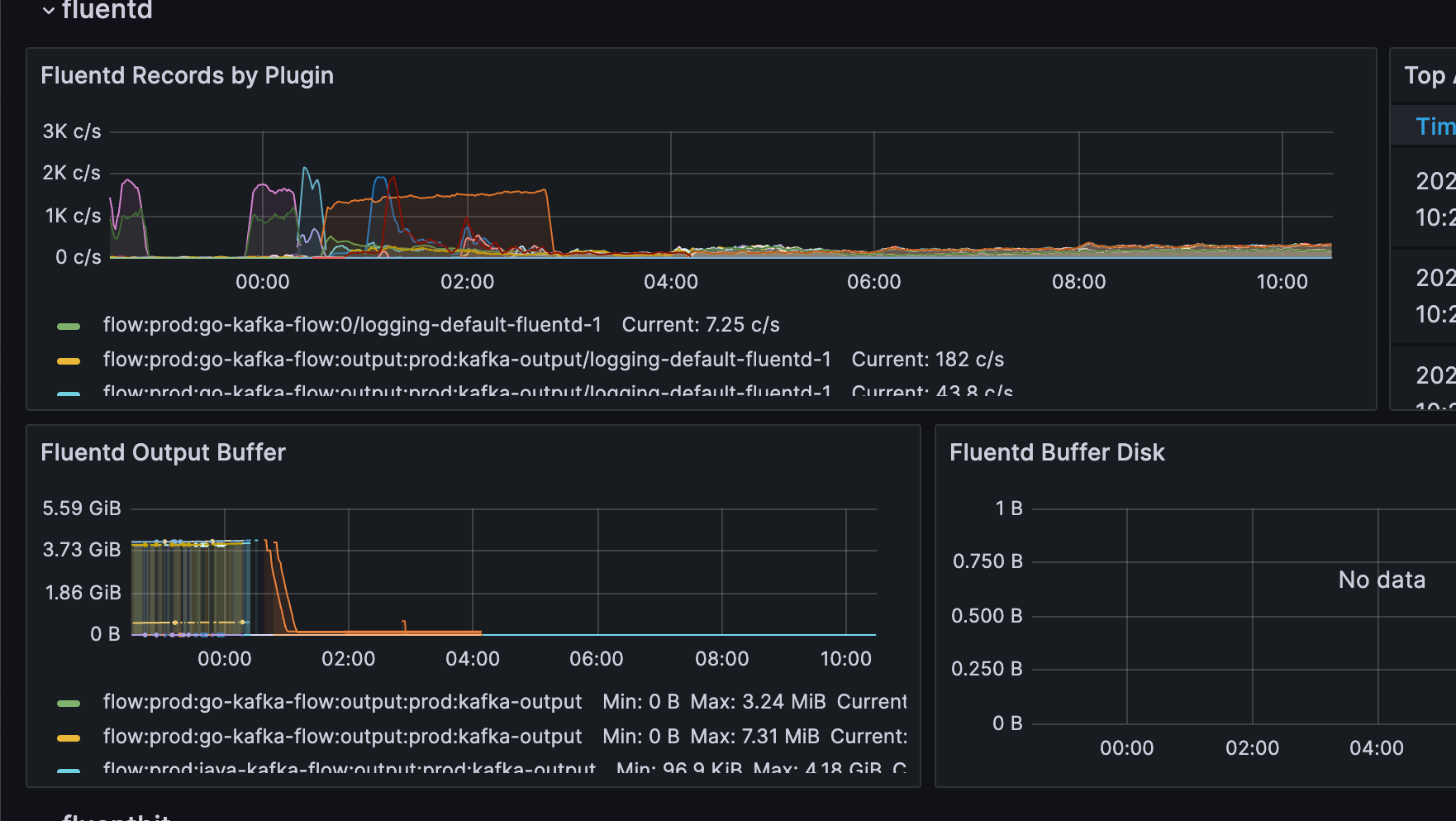
效果
效果也是非常好,如下图 Output Buffer 的图表,之前 Buffer 到接近 4g(我分配的 Cache 大小就是 4g),在改动应用后,迅速就被消费完了。
截止今日,一个多星期了,依然没有遇到性能瓶颈。
总结
我考察了基于Fluent Bit的Kubernetes日志采集方案,最终在Fluent Operator和Logging Operator之间,选择了Fluent Operator,因为它的开箱即用体验做得更好。
初次实施后,尽管Fluent Bit表现稳定,但我遇到了多行日志合并和日志采集暂停的问题,这让我不得不重新思考解决方案。
我决定将日志处理流程分解,让Fluentbit仅负责日志的采集和简单解析,而将过滤和输出任务交给Fluentd处理,同时通过Kafka作为中介,大幅提高了日志处理的效率和系统的稳定性。
在进一步优化过程中,我重新审视了日志框架的选择,最终决定采用Logging Operator,因为它在我关注的几个方面表现更佳,比如服务个性化配置方面和监控能力。
我根据服务的语言维度来划分不同的Flow,并应用不同的采集规则,这使我能更灵活地管理日志采集流程。
然而,当我将日志输出到Kafka时,又遇到了新的挑战:内置的Kafka插件性能不佳。
为解决这个问题,我自定义了镜像,将Fluentd的Kafka插件替换成性能更强的rdkafka,并成功地向Logging Operator社区提交了这一改进。
这一改动大大提高了日志推送到 Kafka的效率,让整个架构运行得更加顺畅。
最后,希望大家不要忽略了基础架构的标准化建设,统一有时候确实能在方方面面提升效率。
